
C++基础
输入输出
标准输入输出对象
iostream库包含两个基础类型istream和ostream,分别表示输入流和输出流,一个流就是一个字符序列。cin是istream类型的对象,被称为标准输入。cout是ostream类型的对象,被称为标准输出。此外,标准库还定义了其它两个ostream对象,分别是cerr(标准错误,输出警告和错误信息)和clog(输出程序运行时的一般性信息)。
输入输出有关符号
1 | cout<<"Hello World!"<<endl; |
- <<是输出运算符,它接受两个运算对象,左侧是ostream对象,右侧是要打印的值。输入运算符>>与它类似。
- endl是一个被称为操纵符的特殊值。写入endl的效果是结束当前行,并将与设备关联的缓冲区中的内容刷到设备中(可以保证程序输出真正写到输出流中,而不是在内存中等待)。
几种输入方式的对比
- cin:
- 不管数据类型是什么,输入一开始都是字符数据,然后cin对象负责将数据转换成其他类型。
- 使用空白(空格,制表符和换行符)来确定字符串的结束位置,在读取字符数组时,cin将只会读取第一个单词。比如输入“Michael Jackon”,cin第一次只会读入“Michael”。
1
2string name;
cin>>name;
- getline:
- 用于读取整行,通过换行符来确定输入的结尾。
- 并不保存换行符,保存字符串时会用空字符来代替换行符。
1
2string name;
getline(cin, name);
- get:
- 工作方式和getline类似,也是读取到行尾。
- 读取到行尾时不丢弃换行符,而是把它留在输入队列中,所以下一次读取的时候会读到换行符。
1
2
3
4string name, dessert;
cin.get(name,50); //第一个参数是字符数组名,第二个参数是接受字符的数目(包括结尾的\0)
cin.get(); //用于去掉换行符
cin.get(dessert,50);
控制流与数据输入
1 | int sum = 0, value = 0; |
使用istream对象作为条件,可以检测流的状态。如果流是有效的,那么检测成功。当遇到文件结束符或无效输入时,istream对象的状态会变为无效,从而使条件变为假,退出循环。(getline函数也可以这么用,它的返回值是输入流对象。如果读取成功,则返回输入流对象本身;如果发生错误,则返回一个错误状态。)
变量和基本类型
基本内置类型
编译器可以根据自身硬件来选择基本类型的大小,但是需要满足约束:short和int型至少为16位,long型至少为32位,并且short型长度不能超过int型,而int型不能超过long型。下面列举在GCC编译器下32位机器和64位机器各个类型变量所占字节数: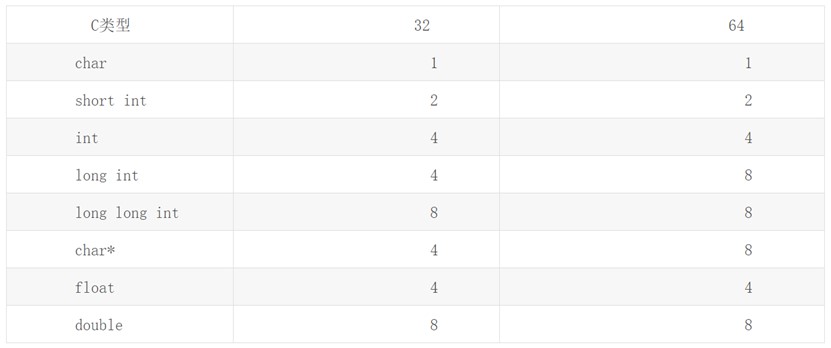
类型转换
隐式转换
- 编译器自动执行的类型转换称为隐式转换,它无需程序员的介入。
- 隐式转换有一些风险,比如隐藏类型不匹配的错误,数据精度降低(double转到int),单参数类构造函数可能会被无意地用于隐式类型转换。
- explicit关键字用于修饰类的构造函数,它禁止隐式调用拷贝构造函数以及类对象之间的隐式转换。
1
2
3
4
5
6
7
8class Test
{
explicit Test(int a);
}
Test aa(10); // OK
Test aa = 10; // 非法,此操作被禁止。加入explicit 可以有效的防止隐式转换的发生,提高程序质量。
Test bb = aa; // 非法,取消了隐式转换,除非重载操作符“=”
显式转换
- 普通的显示转换主要有两种:函数型和类C型。它们可以满足大部分需求,但是这些操作符不加区别地应用于类和指向类的指针上,可能导致代码在语法正确的情况下导致运行时错误。
1
2
3
4double x = 10.3;
int y;
y = int (x); //函数型
y = (int) x; //类C型1
2
3
4
5
6
7
8
9
10
11
12//情况一,通过强制类型转换,不同类型的指针可以随意转换,编译器不报错
Dummy d;
Addition * padd;
padd = (Addition *)&d;
cout << padd->result()<<endl; //Dummy 类中没有result方法,但是编译器不报错
//情况二:将指向const对象的指针转成指向非const
int a = 666;
const int *p1 = &a;
int *p2 = (int *)p1;
*p2 = 999; //经过强制类型转换后,失去了const属性,此时不报错
cout <<"a = "<< a << endl; //a 的值已被更改了 - 为解决以上问题,C++引入了四种类型转换,它们用于不同场景和需求:
- dynamic_cast:用于将父类的指针或引用转换为子类的指针或引用,此场景下父类必须要有虚函数。
- static_cast:用于基本数据类型之间的转换使用(例如float转int,int转char等),有类型指针和void *之间的转换使用,子类对象指针转换成父类对象指针。
- const_cast:用于常量指针或引用与非常量指针或引用之间的转换。
- reinterpret_cast:类似C语言中的强制类型转换,什么都可以转,一般情况下不要使用。
常量和变量
常量
在程序运行时值不可以改变。
- 字面值常量:字面值常量的形式和值决定了它的数据类型,比如20,0x14,3.14,’a’,”Hello World”等。
- 符号常量:
- 宏定义:在预处理中使用,单纯的文本替换。
- const常量:由C++编译器处理,提供类型检查和作用域检查。
变量
在程序运行时值可以改变。
- static:
- 如果用static修饰局部变量,那么这个变量就不会存储在栈区而是放在静态数据区。它的生命周期一直持续到程序结束,而且只在初次运行时进行初始化。
- 如果用static修饰全局变量,那么在其它文件中也可以访问此变量。然而,如果是在源文件(cpp)中去操作这个静态全局变量,则这个静态全局变量只能在当前文件有效,但是在另外一个文件访问此静态变量,会是该变量初始的默认值,不会是其他文件中修改的值。虽然它们有相同的初始内容,但是存储的物理地址并不一样。如果想在不同文件共享同一个全局变量就要用到extern。
- extern:如果想声明一个变量而非定义它,就在变量名前添加关键字extern,而且不要显式地初始化变量。
1
2extern int i; //声明而非定义
extern int i = 0; //定义
复合类型
复合类型是指基于其它类型定义的类型。
引用
1 | int ival = 1024; |
- 引用为对象起了另外一个名字,它本身不是对象。定义引用时,程序把引用和它的初始值绑定在一起,为引用赋值实际上是把值赋给了与引用绑定的对象。
- 引用必须被初始化,而且一旦引用被初始化,就不能改变引用的关系。
- 不能有NULL引用,引用必须与合法的存储单元关联。
指针
1 | double dp1, *dp2; //dp1是double型对象,dp2是指向double型对象的指针 |
- 指针是“指向”另一种类型的复合类型,它本身就是一个对象,允许对指针赋值和拷贝,而且在指针的生命周期内它可以先后指向几个不同的对象。
- 指针无需在定义时赋初值,但在块作用域内的指针如果没被初始化会有一个不确定的值。
- 空指针不指向任何对象,得到空指针最直接的办法就是用字面值nullptr来初始化指针。
- void*是一种特殊的指针类型,可用于存放任意对象的地址。
处理类型
需要一些方法来处理内置类型名字难记的问题。
类型别名
1 | typedef double wages; |
类型别名是某种类型的同义词,它让原本复杂的类型名字变得易于理解和使用。
auto类型说明符
1 | //由val1和val2相加的结果可以推断出item的类型 |
auto类型说明符由C++11新标准引入,它能让编译器替我们分析表达式所属的类型。
其它关键概念
命名空间
当程序用到多个供应商提供的库时,会发生某些名字相互冲突的情况,命名空间可以解决这个问题。
定义
1 | // 第一个命名空间 |
在以上代码中,我们定义了两个命名空间,它们都有函数func。
使用
1 | using namespace std; //引入std中的所有内容 |
std命名空间是C++中标准库类型对象的命名空间。使用上面的第一行代码可以引入std命名空间的所有内容,但是这是一种不保险的做法,因为这样相当于引入了所有的组件名称,重新引发了名字空间泛滥的问题。更好的做法是按需引入,比如第二行代码。另外,头文件不应包含using声明,因为头文件的内容会拷贝到所有引用它的文件中,如果头文件里有某个using声明,那么所有使用了该头文件的文件都会有这个声明,这可能会产生始料未及的名字冲突。
迭代器
迭代器用于访问容器中的元素,所有标准库容器都可以使用迭代器。迭代器有有效和无效之分,有效的迭代器或者指向某个元素,或者指向容器中尾元素的下一位置,其它所有情况都属于无效。
运算符
以下运算符是所有容器的迭代器都支持的。string和vector的迭代器提供了更多额外的运算符,比如iter+=n,>=等。

遍历
1 | for(auto it = s.begin(); it != s.end(); ++it) { |
可以使用迭代器遍历容器中的元素,比如上面的代码在遍历一个set中的元素。
异常处理
1 | int a, b; |
在以上示例中,try语句块里的代码抛出异常,catch子句用来捕获异常并执行对应的操作。C++标准库里定义了一些异常类。例如,stdexcept库里定义的异常类如下所示:

函数重载
1 | void print(const char *cp); //func1 |
如果同一作用域内的几个函数名字相同但形参列表不同,我们称之为重载函数。当调用这些函数时,编译器根据传递的实参类型推断想要的是哪个函数。